
Tihti “kohtan” infosüsteemide dokumentatsioonis või IT lähteülesandes nö “mammut-protsessimudeleid” (st protsessimudeleid, mis ulatuvad üle mitmete lehekülgede ja sisaldavad sadu elemente). Nende vaatamisel tõusevad mul ihukarvad püsti ning mõtlen, kellele küll selline mudel mõeldud on ja kes seda üldse lugeda suudab? Minul endal tekib automaatselt selliste suurte mudelite puhul tunne, et ma ei tahagi üldse neisse süveneda, kuna ma ei suuda neile peale vaadates hoomata mudeli skoopi. Tänases blogiposituses räägin, miks on oluline jälgida äriprotsessi mudeli suurust ning milliseid nippe saad kasutada normaalse suurusega mudelite modelleerimiseks.
Miks on oluline jälgida äriprotsessi mudeli suurust?
Üks peamine põhjus on see, et mudel oleks loetav ning selle skoop ja loogika oleksid hoomatavad. Mida see tähendab? Kui mudel sisaldab sadu erinevaid elemente, siis selleks, et see ühele lehele (nt. A4 lehele) või läptopi ekraanile ära mahuks, peab seda kõvasti vähendama. See omakorda tähendab seda, et ilma sisse suurendamata ei ole loetavad äriprotsessi algus- ja lõppsündmuste kirjeldused (need on väga olulised mudeli skoobi mõistmisel), samuti ei ole loetavad tegevuste ega ka otsustuskohtade tekstilised kirjeldused. Kui nüüd nimetatud elementide lugemiseks mudelisse sisse suurendada, siis ei näe enam tervikpilti. Ja kui korraga ei näe ühel lehel või ekraanil kogu mudeli tervikpilti, siis ei ole kerge hoomata mudeli üldist loogikat – nt mitu osapoolt on seotud, kui palju on protsessi voogudes hargnemisi, kui palju esineb protsessis katkestavaid lõppsündmuseid jne.
Tuletan taaskord meelde, et mudel on teatud üldistus reaalsest maailmast ning sinna ei ole mõistlik modelleerida igat pisikest detaili. Mudeleid kasutataksegi selleks, et reaalsest maailmast luua ülevaatepilt, mille eesmärk on anda lugejale tervikvaade. Tervikvaate jaoks ei ole vaja lahti seletada kõiki antud äriprotsessi detaile. Need võivad tulla antud mudelile juurde mõnel teisel kujul – nt tekstilise kirjeldusena, mõne teise täiendava mudelina või hoopis antud mudeli alamprotsessis.
Nii nagu lugeja ei suuda hoomata suurte mudelite loogikat ja skoopi, ei suuda seda tihti teha ka modelleerija ise. Ja kui modelleerijal ei käi oma mudelist nö jõud üle, siis võib see kaasa tuua notatsioonile mittevastavad vigased mudelid. Paljude elementidega mudelite puhul tekib kindlasti rohkem ja keerukamaid otsustuskohti, mille puhul peab jälgima, kas nad on õigesti koondatud. Samuti tekib vajadus mudeli elemente rohkem paigutada, et elemendid omavahel ei kattuks ning mudel säilitaks arusaadavuse. Olen täheldanud suurte mudelite puhul ka ebaühtlast detailsuse astet. See tähendab, et modelleerija on hakanud ülidetailselt modelleerima ja siis poole peal avastanud, et mudel on juba väga suureks läinud. Selle tulemusena üritab ta mudelit kiiresti “koomale tõmmata” ehk hakkab modelleerima üldisema detailsusastmega. Kui modelleerimisel ei ole läbivalt jälgitud sama detailsuse astet, siis see jällegi raskendab mudeli arusaadavust.
Milliste nippide abil piirata äriprotsessi mudeli suurust?
- Esimene nipp mudeli suuruse piiramiseks on enne joonistamist läbi mõelda ja ära täita äriprotsesside raamistik (sellest kirjutasin täpsemalt siin). Äriprotsesside raamistiku kaudu mõtleb modelleerija läbi konkreetse modelleeritava äriprotsessi skoobi – st sellega paneb ta paika protsessi algus- ja lõppsündmused, seotud osapooled, protsessi eesmärgi jne. Need kõik annavad modelleerijale ette nö piirid, milles ta võiks modelleerimise raames püsida. Kui nüüd modelleerija ei ole neid piire läbi mõelnud, siis võibki juhtuda nii, et ta hakkab modelleerima ning modelleerib ühte mudelisse kogu maailma kokku.
- Teine nipp on enne joonistamist paika panna see, kelle perspektiivist mudelit joonistatakse. Sellest, et igal äriprotsessil on mitu nägu/perspektiivi, oli täpsemalt juttu siin. Tihti paneb modelleerimise eesmärk paika selle, kelle perspektiivist on vaja mudelit joonistada. Näiteks kui eesmärk on süsteemi arendamisel süsteemi kasutajaga valideerida, kuidas tema poolt süsteemis läbiviidavad tegevused omavahel seotud on, siis tuleb modelleerida lõppkasutaja perspektiivist. See tähendab, et tuleb rõhku panna detailsemalt lõppkasutaja tegevustele ning vähem detailsemalt süsteemi tegevustele. Kui aga on vaja arendusmeeskonnale selgitada, kuidas süsteem konkreetset äriprotsessi toetama hakkab, siis on mõistlik detailsemalt lahti modelleerida just süsteemi enda tegevused.
- Kolmas nipp on hierarhiline modelleerimine. Mida see tähendab? See tähendab seda, et modelleerija modelleerib suuri/keerulisi äriprotsesse kihiliselt. Näiteks esimene kiht on kõige üldisem, selle eesmärk on näidata ära konkreetse äriprotsessi skoop. Mudelis kajastatud tegevused on pigem tegevuste grupid (alamprotsessid). Sisuliselt koosnebki esimese taseme protsessimudel algus- ja lõppsündmustest ning erinevatest alamprotsesside järgnevustest. Teine kiht on selline, millel on nt. üks esimese kihi alamprotsess lahti modelleeritud. Teise kihi algus- ja lõppsündmus on konkreetse alamprotsessi lõppsündmus, osapooltena on välja toodud ainult konkreetse alamprotsessi osapooled ning tegevustena ainult konkreetse alamprotsessi tegevused. Kui on tegemist väga keeruliste protsessidega, siis võib olla vajadus modelleerida eraldi detailselt veel kolmas, neljas, viies jne äriprotsessi kiht.
Hierarhiline modelleerimine
Väga hea näide hiearhilisest modelleerimisest on toodud Jakob Freundi ja Bernd Rückeri raamatus “Real Life BPMN”.
Allaolev joonis kajastab värbamise protsessi kõige üldisemat taset. Joonist lugedes on kenasti aru saada, et värbamise protsess algab sellest kui tekib vaba töökoht ning lõppeb sellega, kui vaba töökoht on täidetud. Näeme, et nimetatud protsessiga on seotud firmasiseselt kaks osakonda – HR ja värbamise osakond. Ning seotud on üks fimaväline osapool, nimelt kandideerija. Samuti näeme, et enamus tegevusi on protsessis modelleeritud alamprotsessidena (tegevustel on kastis pluss märk) ning antud joonisel ei ole nende alamprotsesside loogikat detailsemalt lahti modelleeritud.

Allolev joonis kajastab värbamise protsessi natuke detailsemat voogu. Iga osapool on “tõstetud” oma ujumisbasseini ja seetõttu on neil igalühel oma algus- ja lõppsündmus. Osapoolte vahel on näidatud detailsemalt info liikumist sõnumivoogude vahendusel. Samuti on sisse toodud üks otsustuskoht – kas kandideerimise taotluse laekus?
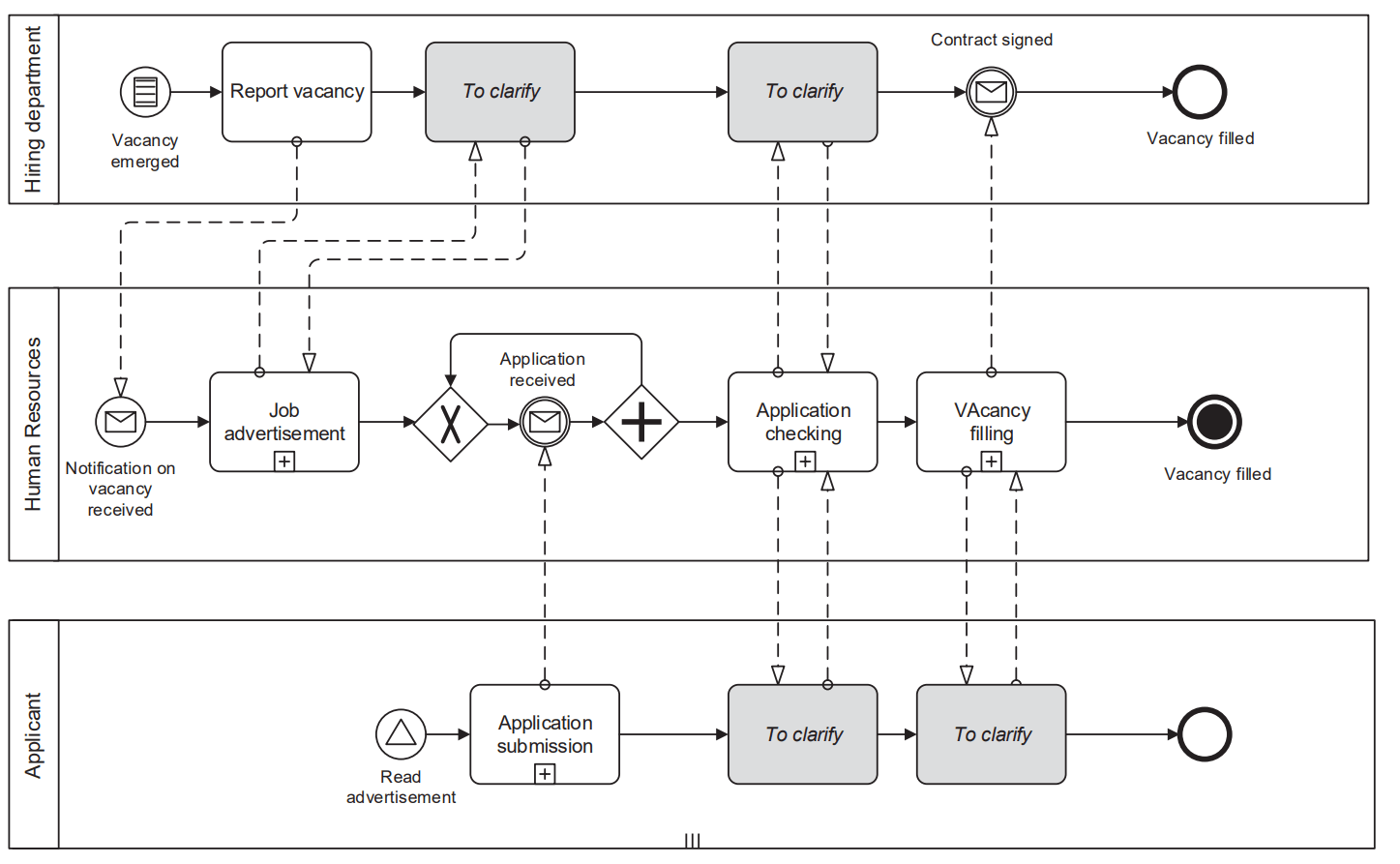
Allolevalt jooniselt näed sama protsessi, mis on veelgi detailsemalt lahti modelleeritud. Sellelt on näha, et osapooltena on sisse toodud infosüsteem, mis värbamise protsessi toetab ning välja jäetud kandideerija. Seotud osapoolte ujumisbasseinides on täpsustatud konkreetsemad ujumisrajad. Protsessis esineb juba rohkem erinevaid otsustuskohti ning paljud tegevused on lahti modelleeritud (st puudub viide alamprotsessile).

Pikk jutt lühidalt ja konkreetselt – palun mõtle enne modelleerimist läbi, kes hakkavad sinu mudeleid tarbima, sellest lähtuvalt pane paika oma mudeli skoop ning modelleeri hierarhiliselt. Sellega vähendad tõenäosust, et modelleerid mammut-protsessimudelit, mida keegi ei suuda lugeda.
Koostöös IT koolitusega olen läbi viimas äriprotsesside kirjaoskuse teemalist koolitust – https://koolitus.ee/koolitused/9756/koolitus-ariprotsesside-kirjaoskuse-koolitus. Koolitusel tutvustan juhiseid heade protsessimudelite loomiseks, sh. räägin ka hierarhilise modelleerimise olulisusest.
Kui sind kõnetavad teemad, mida oma blogis kajastan, siis võta minuga julgelt ühendust!