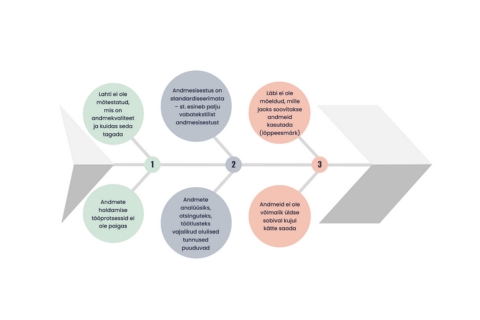
Mõnda aega tagasi kirjutasin Ravimiameti apteegistatistika väljaandesse “20 aastat apteegistatistikat Eestis” ühe artikli andmekvaliteedist ning andmete kogumise ja töötlemise tööprotsessidest. Sellest on ajendatud ka minu järgmine blogipostitus, milles toon välja enda tähelepanekud andmekvaliteediga seoses.

Kõikide tööprotsesside käigus tekib teatud hulk andmeid. Näiteks võivad meie igapäevase poeskäigu kohta tekkida poe andmebaasi kliendikaardi kasutamisega seotud andmed (arve summa ja arveridade arv, ostetud tootegrupid, rakendunud soodustused jne). Nimetatud andmed on eelkõige vajalikud poe turundusega seotud tööprotsessides (nt. kliendilojaalsusprogrammi loomise ja uuendamise protsessis) aga võivad olla heaks sisendiks ka eraisiku eelarve ja rahaasajade planeerimise tööprotsessis.
Mis on andmekvaliteet?
Kvaliteet on vastavus kokkulepitule ning kui me räägime andmekvaliteedist, siis kajastab see seda, kas andmed on kogutud, loodud, talletatud, töödeldud vastavalt kokkuleppele. Kui kokkuleppe kohaselt peab andmeid kirjeldama klassifikaatorite kaudu ning seda ei ole andmete kogumisel niimoodi rakendatud, siis ei teki ka kvaliteetseid andmed.
Näiteks poeskäigu raames tekkivate andmete puhul on väga oluline läbi mõelda, millisel kujul salvestatakse kliendi ostu info. Ütleme, et näiteks kliendi poolt ostetud tootegruppide info on vaja salvestada klassifikaatorite kaudu. Selline andmetalletus võimaldaks hiljem neid andmeid hõlpsalt analüüsida ja selle pinnalt otsuseid teha. Oletame, et poe iseteeninduse kassasüsteem salvestab millegipärast kokkulepitud andmetalletuse asemel kogu info ühte suurde vabateksti välja. Sellisel juhul on tegemist halva andmekvaliteediga, kuna need andmeid ei ole hiljem lihtsasti ja eesmärgipäraselt kasutatavad.
Kuidas tagada kvaliteetsed andmed?
Kvaliteetsed andmed tekivad läbimõeldud andmete kogumise ja töötlemise tööprotsessidest, mille toetamiseks on loodud kas infosüsteemid või struktureeritud andmete kogumise mallid. Selleks et andmeid koguda, peab kõigepealt tuvastama, kust ja kelle käest neid kõige mõistlikum oleks koguda.
Alati ei ole vaja täiesti uusi andmeid koguda, vaid tuleks analüüsida, kas kusagil on juba sarnaseid andmeid kogutud. Ressursi säästliku kasutuse vaatest on juba ükskord kogutud andmete taaskasutus väga oluline! Seega peaks kindlasti proovima taaskasutada võimalikult palju juba kogutud andmeid. Selle mõttega haakub väga hästi ka reaalajamajanduse kontseptsioon.
Järgmine võtmeküsimus on, millisel kujul andmeid oleks mõistlik koguda. Andmete kogumist toetavate infosüsteemide või mallide puhul on väga oluline, et andmeid kogutakse justnimelt sellisel kujul ja sellistele reeglitele vastavalt, nagu lõppeesmärgi jaoks vaja on. See tähendab tihipeale seda, et infosüsteemides ja andmete kogumise mallides on andmete sisestajale ette määratud, mis kujul ta saab andmeid sisestada, ning sisestades kontrollitakse ka seda, et andmed vastaksid etteantud ärireeglitele.
Kvaliteetsed andmed saavad tekkida ainult siis, kui on lahti mõtestatud andmete kogumise ja töötlemise tööprotsessid ning pandud paika, millises etapis andmetega midagi tehakse. Kui andmete kogumise etapis suudetakse koguda väga kvaliteetsed andmed, siis see tähendab vähem tööd andmetöötluse etapis. Ja vastupidi, kui andmete kogumisel ei ole andmekvaliteet fookuses, siis see tähendab väga palju tööd andmetöötluse etapis. Siinkohal peaks eraldi rõhutama, et tihti ei olegi kogutud „prügi” võimalik andmetöötlusega korda teha ja seega ei pruugi kõikidest kogutud andmetest üldse kasu olla.
Mida jälgida andmete kogumisel ja haldamisel?
Kõige hullem variant on see, kui kogu andmestik on talletatud ühte vabateksti välja. Selliselt kogutud andmed sisaldavad tavapäraselt palju sisestusvigu ning neid on ühtsetel alustel väga keeruline (tihti isegi võimatu) analüüsida. Samuti on selliselt talletatud andmetest keeruline midagi üles leida. Seega oleks esimene soovitus koguda andmeid standardiseeritult ehk klassifikaatorite kaudu.
Andmete kogumisel peab määrama, mis eesmärgil neid kogutakse ja mida soovitakse hiljem andmetega peale hakata. Kui on soov andmeid teatud lõigetes otsida, analüüsida, filtreerida, grupeerida vms, siis on oluline, et selliste toimingute jaoks vajalikud tunnused oleksid andmetes esindatud.
Kui kogutavaid andmeid on vaja analüüsida koos mingite teiste andmekogude andmetega, siis on oluline, et andmetes talletatakse ka kogumise või töötlemise käigus kõik vajalikud seosed teiste andmete/andmekogudega.
Tänapäeval peaks uute süsteemide arendamisel olema kõige olulisem nõue see, et kogutud andmeid peab olema võimalik hõlpsalt süsteemist kätte saada. Mina olen erinevate projektide raames väga palju põrkunud probeemi otsa, et teatud süsteemist ei olegi võimalik andmeid kätte saada ning see pärsib andmete taaskasutamist.
Andmete haldamisel tuleks paika panna andmete halduse tööprotsessid ja läbi mõelda järgmised küsimused:
- Kas ja kui tihti andmeid uuendatakse? Kuidas toimub andmete uuendamise töövoog?
- Kas ja kui tihti klassifikaatoreid uuendatakse? Kuidas toimub klassifikaatorite haldamine? Kas eri hetkedel laekunud andmetes on vaja arvestada klassifikaatorite erinevaid versioone?
- Milline on andmekvaliteet ja kuidas seda tagatakse?
- Kas andmeid kustutatakse? Kellel on õigus andmeid vaadata, lisada, muuta, kustutada?
- Kuidas on võimalik andmeid jagada? Mõtestada lahti erinevad andmeid tarbivad sihtrühmad ja neile vajalikud andmete tarbimise kanalid!
Koostöös IT koolitusega olen läbi viimas äriprotsesside kirjaoskuse teemalist koolitust, millele käigus puudutame samuti tööprotsesside ja andmete/andmevoogude vahelist seost – https://koolitus.ee/koolitused/9756/koolitus-ariprotsesside-kirjaoskuse-koolitus.
Kui sind kõnetavad teemad, mida oma blogis kajastan, siis võta minuga julgelt ühendust!